

Synthetic Data Services
Overview
The Synthetic Data Generation Service in the Health-X Innovation Sandbox
provides a secure and compliant platform to generate synthetic or test
data to support innovation experimentation closer to real-world, production-like
environments.
This service is especially useful for project teams that require massive
data for machine learning model training, software testing, behavioral
simulations, and building product demos — without compromising data privacy.
Why Synthetic Data?
• Safe Experimentation: Enables project teams and external
collaborators to test their ideas without exposing real personal data.
• Compliance Ready: Mimics the statistical structure of
real data while ensuring compliance with privacy regulations.
• High Volume & Fast: Allows teams to generate large
volumes of test data quickly and efficiently.
• Production-Like Testing: Simulates realistic datasets
to validate solutions in environments closer to production.
Key Features
• Structured Tabular Data (Phase 1): Generation of high-quality,
synthetic tabular datasets that resemble real production data while preserving
data privacy.
• Pre-Loaded Datasets: Synthetic datasets can be pre-loaded
from open sources (e.g., Synthea)
for faster prototyping and testing.
• Customizable Coverage: Configure datasets to suit your
test scenarios, such as specific demographics or use cases.
• Collaboration-Friendly: Teams can download relevant
dataset copies from the HXIS Data Hub, preserving dataset integrity by
avoiding overwrite conflicts.
Project Objectives
• Quality: Produce synthetic data that is balanced and
unbiased.
• Productivity: Speed up the testing cycle with quickly
generated datasets.
• Volume: Supplement limited or non-existent datasets.
• Coverage: Enable targeted, scenario-specific testing.
• Compliance: Reduce risks related to non-compliance and
sensitive data exposure.
Innovation Impact
• Accelerates Prototyping: Especially valuable for projects
where production data doesn’t exist yet (e.g., new applications).
• Enhanced Privacy: Avoids the use of actual PII while
retaining the statistical integrity of the data.
• Reuse for Multiple Scenarios: Synthetic datasets can
be reused across different test cases and projects, increasing testing
efficiency.
• Data Governance Alignment: Follows governance best practices,
including data sourcing from clusters/agencies with appropriate oversight.
Future Plans
Synapxe aims to expand Synthetic Data Services to support more complex
data types, including:
• Unstructured data such as clinical notes
• Images and video for use in computer vision and AI model development
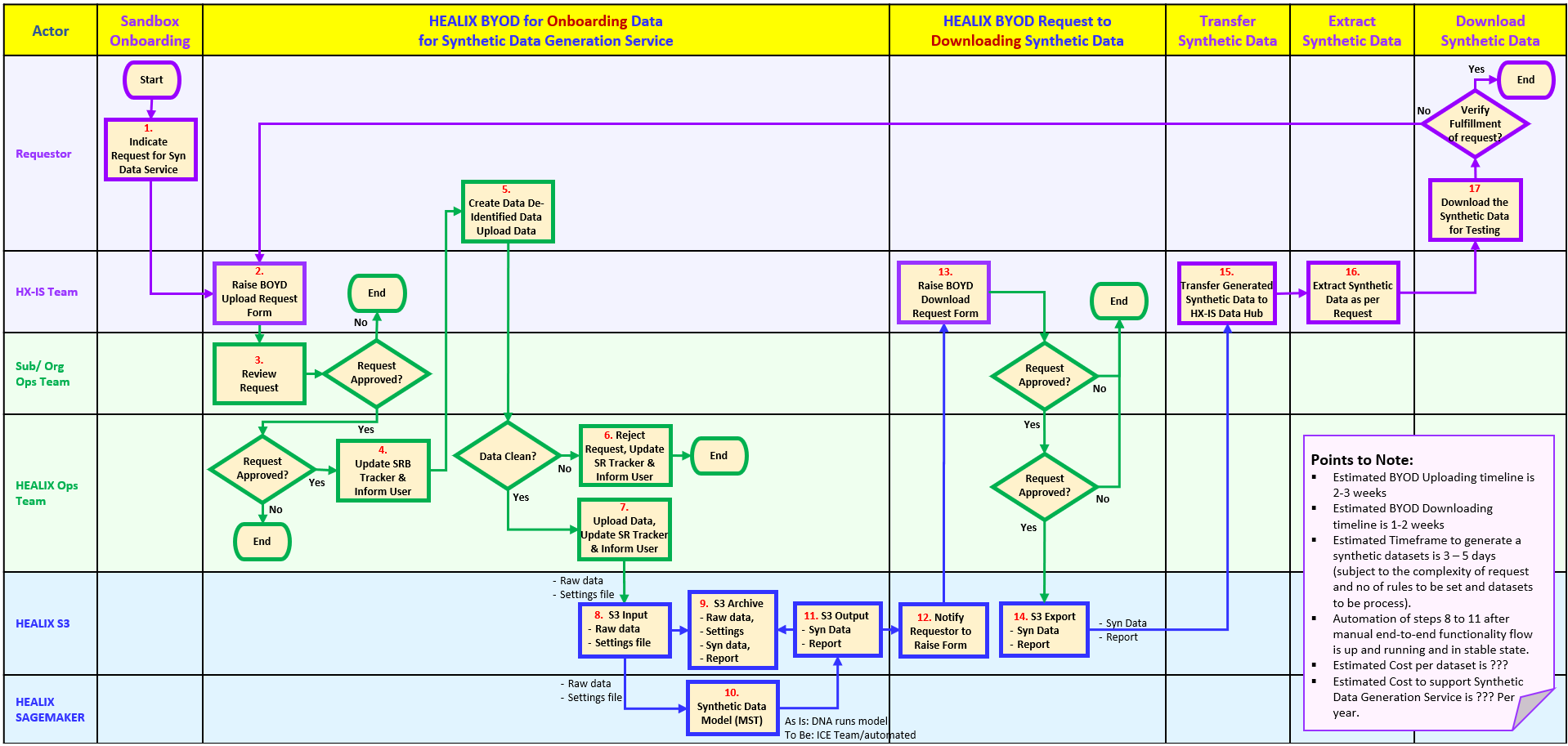
Synthetic Data Generation Process Flow
Get Started
Access the service via the SynData Service and start building realistic, privacy-preserving datasets for your next innovation project.